Note from the Editors: These posts are part of an ongoing conversation about text-mining and statistical analysis of language. To further investigate the methods used, please follow the links provided by the authors.
Identifying diction that characterizes an author or genre: why Dunning’s may not be the best method.
By Ted Underwood
- “The basic question is just this: if I want to know what words or phrases characterize an author or genre, how do I find out? As Ben Schmidt has shown in an elegantly visual way,simple mathematical operations won’t work. If you compare ratios (dividing word frequencies in the genre A that interests you by the frequencies in a corpus B used as a point of comparison), you’ll get a list of very rare words. But if you compare the absolute magnitude of the difference between frequencies (subtracting B from A), you’ll get a list of very common words.” Read Full Post Here.
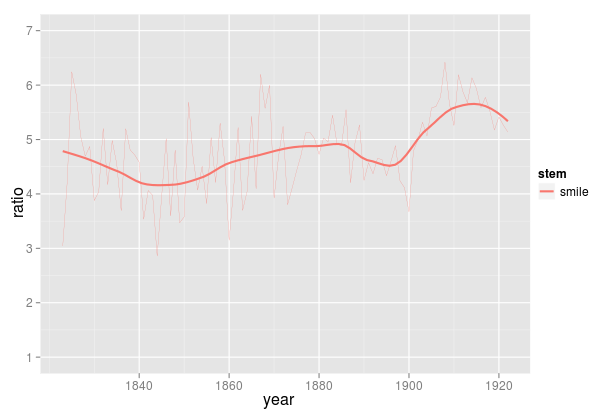
By Ben Schmidt
- Anyhow, I think this is what we need the Dunnings for: extracting a list of words that are worth analyzing a bit more by hand. With each of these, we know there’s a real difference: we can then plot the degree of over-representation over time. I’m going to do this for the top 96 words. (Why 96? Why not?) So for instance, here’s the plot for “smile.” (Including “smiling,” “smiles,” etc.)