
Below is the text of a talk delivered at the Digital Antiquarian conference in May 2015. (The slides can be downloaded from the conference website). I am grateful to the conference organizers, Molly O’Hagan Hardy and Tom Augst, and the staff of the American Antiquarian Society, for the opportunity to present my work “under the dome.”
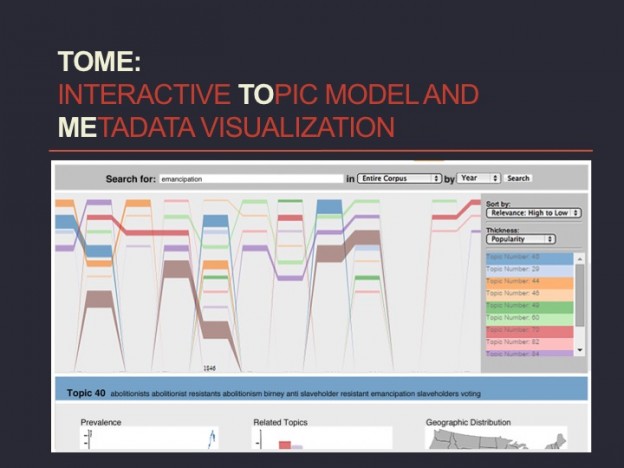
When it comes to the digital humanities, my most strongly-held belief is that the field, in its most powerful instantiation, can perform a double function: facilitating new digital approaches to scholarly research, and just as powerfully, calling attention to what knowledge, even with these new approaches, still remains out of reach. I will illustrate this double function through the example of the TOME project, a digital tool that I’ve been developing with my colleague at Georgia Tech, Jacob Eisenstein, and a team of several graduate and undergraduate students. Our tool employs topic modeling, a technique that derives from the field of machine learning, to support the interactive thematic exploration of digitized archival collections. (And more on that soon).
But since our test archive consists of a set of abolitionist newspapers, including many held at the AAS, I thought I’d use this particular occasion to work through some of the things that our tool, and the process of its development, have taught us about nineteenth century knowledge production, before considering how digital tools, more generally, do—and do not—help to bring that process of knowledge production to light.
To this end, I want to introduce two concepts that, to me, strongly resonate in both historical and contemporary contexts. These are carework and codework, as the title of this talk indicates, and I want to begin by briefly explaining what I mean by each.
Source: The Carework and Codework of the Digital Humanities | Lauren Klein